Zajęcia 6
11. Obiektowy model dokumentu
Obiektowy model dokumentu (ang. Document Object Model - DOM) określa, jak przeglądarka powinna utworzyć model HTML strony internetowej, a także jak JavaScript może uzyskać dostęp do zawartości strony i modyfikować tę zawartość podczas wyświetlania strony w oknie przeglądarki. Model DOM nie jest częścią HTML ani JavaScript - jest to oddzielny zbiór reguł, implementowany przez producentów wszystkich najważniejszych przeglądarek internetowych.
11.1. Drzewo modelu DOM
Kiedy przeglądarka wczytuje stronę internetową, tworzy jej model - tzw. model drzewa DOM, który jest przechowywany w pamięci zajmowanej przez przeglądarkę. Składa się z czterech podstawowych typów węzłów.
Węzeł document jest to węzeł, który znajduje się w korzeniu drzewa modelu DOM. Przedstawia on całą stronę (i jednocześnie odpowiada obiektowi document, który poznaliśmy już wcześniej). Kiedy uzyskujemy dostęp do dowolnego węzła elementu, atrybutu lub tekstu, przechodzimy do niego za pomocą węzła document. To punkt wyjścia dla wszystkich wizyt w drzewie modelu DOM.
Węzły elementów są to węzły, które odpowiadają poszczególnym elementom strony HTML. Aby uzyskać dostęp do drzewa modelu DOM, należy rozpocząć od wyszukiwania elementów. Po znalezieniu żądanego elementu mamy dostęp do węzłów jego tekstu i atrybutu, o ile zachodzi potrzeba.
Otwierający znacznik elementu HTML może zawierać atrybuty, które w drzewie modelu DOM są prezentowane przez węzły atrybutów. Węzły atrybutów nie są elementami potomnymi zawierającego go elementu, ale stanowią część dokumentu. Gdy uzyskamy dostęp do elementu, dostępne będą określone metody i właściwości JavaScript pozwalające na odczyt lub zmianę atrybutów tego elementu.
Gdy uzyskamy dostęp do węzła elementu, możemy przejść do tekstu przechowywanego w tym elemencie. Tekst znajduje się we własnym węźle tekstowym. Węzły tekstowe nie mogą mieć elementów potomnych. Jeżeli element zawiera tekst oraz inny element potomny, to ten element potomny nie jest potomkiem węzła tekstowego, ale raczej obejmującego go elementu. To pokazuje, że węzeł tekstowy zawsze jest nową gałęzią w drzewie modelu DOM, z której nie wywodzą się żadne dalsze gałęzie.
Każdy węzeł jest dokumentem wraz z metodami i właściwościami. Skrypty uzyskują dostęp do drzewa modelu DOM (nie pliku źródłowego HTML) i uaktualniają je. Wszelkie zmiany wprowadzone w drzewie modelu DOM są odzwierciedlane w przeglądarce.
Przykład 11.1.
Dla kodu źródłowego strony:
<!DOCTYPE html>
<html>
<head>
<title>Przykład</title>
</head>
<body>
<h1 id="header">Przykład 11.1.</h1>
<span>Tu jest treść elementu <span></span>
</body>
</html>
drzewo modelu DOM będzie wyglądać następująco:
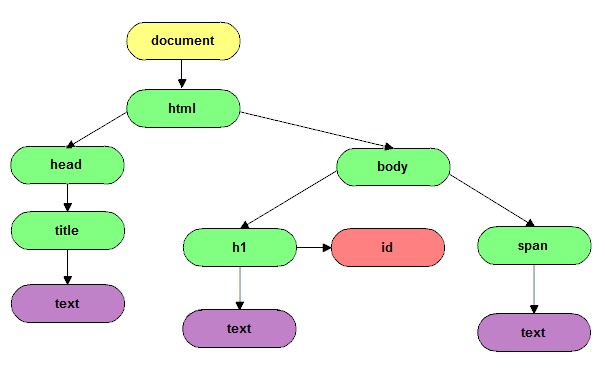
Ćwiczenie 11.1.
Narysuj drzewo modelu DOM dla strony o poniższym kodzie źródłowym:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div class="wrapper">
<h1>Zadanie 11.1.</h1>
<p id="paragraph">Tu jest treść akapitu</p>
</div>
</body>
</html>
11.2. Buforowanie zapytań modelu DOM
Metody wyszukujące elementy w drzewie modelu DOM są nazywane zapytaniami modelu DOM. Jeżeli z danym elementem musimy pracować więcej niż jeden raz, rozsądnym rozwiązaniem jest użycie zmiennej do przechowywania wyniku danego zapytania. Kiedy programiści mówią o przechowywaniu elementów w zmiennych, tak naprawdę mają na myśli przechowywanie w zmiennej położenia elementu (lub elementów) w drzewie modelu DOM. Właściwości i metody tego węzła elementu działają na zmiennej.
Metody wyszukujące elementy poznaliśmy na poprzednich zajęciach. W związku z tym wykonajmy poniższe ćwiczenie:
Ćwiczenie 11.2.
Dany jest kod źródłowy strony:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div class="wrapper">
<h1 class="example">Zadanie 11.2.</h1>
<ul>
<li id="li-1">Punkt 1.</li>
<li id="li-2">Punkt 2.</li>
<li id="li-3">Punkt 3.</li>
<li id="li-4">Punkt 4.</li>
</ul>
<p class="example">Tu jest treść akapitu</p>
</div>
</body>
</html>
Napisz skrypt języka JavaScript, który wypisze (w konsoli) zawartość listy oraz zawartość elementów o klasie example.
11.3. Poruszanie się po modelu DOM
Kiedy mamy węzeł elementu, możemy wybrać inny, powiązany z nim element, wykorzystując w tym celu pięć właściwości. Nazywa się to poruszaniem się po modelu DOM.
Omówimy teraz wspomniane pięć właściwości:
- parentNode - ta właściwość wyszukuje węzeł elementu dla elementu nadrzędnego w kodzie HTML. Np. dla kodu z ćw. 11.2. dla pierwszego elementu <li> właściwość ta zwróci nam <ul>;
- previousSibling oraz nextSibling - te właściwości powodują wyszukanie odpowiednio poprzedniego i następnego węzła równorzędnego. Jeśli taki węzeł nie zostanie znaleziony dostaniemy null;
- firstChild oraz lastChild - te właściwości powodują wyszukanie odpowiednio pierwszego i ostatniego elementu potomnego dla elementu bieżącego. Podobnie jak wyżej, jeśli taki element nie zostanie znaleziony dostaniemy null.
Poza Internet Explorerem większość przeglądarek traktuje znaki odstępu między elementami jako węzły tekstowe. Dlatego też omówione wyżej właściwości (oprócz parentNode) zwracają różne elementy w zależności od przeglądarki.
Więcej informacji o hierarchii węzłów w modelu DOM znajdziesz na stronie http://kursjs.pl/kurs/hierarchia/hierarchia_nody.php
Ćwiczenie 11.3.
Działamy na kodzie z ćwiczenia 11.2. Napisz skrypt języka JavaScript, który pobierze do zmiennej element <li id="li-2">. Wypisz (w konsoli) zawartość jego poprzednika i następnika.
11.4. Węzły atrybutów
Przanalizujmy przykład:
Przykład 11.2.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div class="wrapper">
<h1 id="header">Przykład <i>11.2.</i></h1>
<p id="paragraph">Tu jest <u>treść</u> akapitu</p>
</div>
<script src="app.js"></script>
</body>
</html>
Plik app.js:
var el = document.getElementById('header');
if (el.hasAttribute('id')) { // sprawdzamy, czy element ma atrybut 'id'
var attr = el.getAttribute('id'); // pobieramy wartość atrybutu 'id'
console.log(attr);
el.id = "nowy-id"; // zmieniamy wartość atrybutu 'id';
}
if (el.hasAttribute('class')) { // sprawdzamy, czy element ma atrybut 'class'
var attr = el.getAttribute('class'); // pobieramy wartość atrybutu 'class'
console.log(attr);
}
else {
el.setAttribute('class', 'nowa-klasa'); // dodajemy do elementu atrybut 'class' o wartości 'nowa-klasa'
var attr2 = el.className; // przypisujemy do zmiennej nazwę klasy
console.log(attr2);
el.removeAttribute('id'); // usuwamy atrybut 'id'
console.log(el.getAttribute('id'));
}
Ćwiczenie 11.4.
Dla strony o kodzie źródłowym HTML z przykładu 11.2. napisz skrypt języka JavaScript, który akapitowi nada klasę akapit i zmieni identyfikator na zmieniony.
11.5. Pobieranie i uaktualnianie zawartości elementu
Aby pracować z zawartością elementów można:
- przejść do węzłów tekstowych - sprawdza się to najlepiej, gdy element zawiera jedynie tekst bez żadnych innych elementów;
- pracować z elementem nadrzędnym - w ten sposób można uzyskać dostęp do jego węzłów tekstowych i elementów potomnych. Sprawdza się to najlepiej, gdy element posiada węzły tekstowe i równorzedne elementy potomne.
Przeanalizujmy poniższy przykład:
Przykład 11.3.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div class="wrapper">
<h1 id="header">Przykład <i>11.3.</i></h1>
<p id="paragraph">Tu jest <u>treść</u> akapitu</p>
</div>
<script src="app.js"></script>
</body>
</html>
Plik app.js:
var element = document.getElementById('header');
console.log(element.firstChild.nodeValue); // wynikiem będzie "Przykład "
console.log(element.lastChild.firstChild.nodeValue) // wynikiem będzie "11.3."
console.log(element.nodeValue); // wynikiem będzie "null"
console.log(element.firstChild.nextSibling.nodeValue); // wynikiem będzie "null"
element.firstChild.nodeValue = "Zmieniony przykład ";
Ćwiczenie 11.5.
Do czego służy właściwość nodeValue? Dlaczego w przykładzie powyżej dwa ostatnie polecenia console.log() skryptu zwracają wartość null?
Przykład 11.4.
Inny skrypt do strony o kodzie źródłowym z przykładu 11.3.:
var element = document.getElementById('header');
console.log(element.textContent); // wynikiem będzie "Przykład 11.3."
console.log(element.innerHTML); // wynikiem będzie "Przykład <i>11.3.</i>"
element.textContent = "Zmieniony przykład 11.3.";
var element2 = document.getElementById('paragraph');
element2.innerHTML = '<u>Zmieniony</u> akapit';
console.log(element2.innerHTML); // wynikiem będzie "<u>Zmieniony</u> akapit"
Ćwiczenie 11.6.
Jak zachowują się właściwości textContent i innerHTML?
11.6. Dodawanie elementów w drzewie modelu DOM
Przeanalizujmy poniższy przykład:
Przykład 11.5.
Działamy na kodzie HTML z przykładu 11.2.:
// Utworzenie nowego elementu i przechowywanie go w zmiennej.
var newElement = document.createElement('span');
// Utworzenie węzła tekstowego i przechowywanie go w zmiennej.
var newText = document.createTextNode('To jest nowy element.');
// Dołączenie nowego węzła tekstowego do nowego elementu.
newElement.appendChild(newText);
// Wyszukanie miejsca, w którym powinien być dodany nowy element.
var position = document.getElementsByClassName('wrapper')[0];
// Wstawienie nowego elementu we wskazanym miejscu.
position.appendChild(newElement);
Ćwiczenie 11.7.
Dany jest kod źródłowy strony:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<div class="wrapper">
<h1 class="example">Zadanie 11.7.</h1>
<ul>
<li id="li-1">Punkt 1.</li>
<li id="li-2">Punkt 2.</li>
<li id="li-3">Punkt 3.</li>
<li id="li-4">Punkt 4.</li>
</ul>
<p class="example">Tu jest treść akapitu</p>
</div>
</body>
</html>
Dla powyższej strony napisz skrypt języka JavaScript, który do listy doda nowy element o treści Punkt 5. z identyfikatorem li-5.
11.8. Usuwanie elementów z drzewa modelu DOM
Przeanalizujmy poniższy przykład:
Przykład 11.6.
Dalej działamy na kodzie HTML z przykładu 11.2.:
// Element przeznaczony do usunięcia.
var removeElement = document.getElementById('header');
// Jego element nadrzędny.
var containerElement = removeElement.parentNode;
// Usunięcie elementu.
containerElement.removeChild(removeElement);
Ćwiczenie 11.8.
Dla strony o kodzie źródłowym HTML z ćwiczenia 11.7. napisz skrypt języka JavaScript, który usunie wszystkie elementy listy, a następnie sam element <ul>.
Zadania domowe
Zadanie 1.
Wykonaj czwartą fazę tworzenia projektu - “ożywienie” aplikacji przy pomocy języka JavaScript. Każda większa zmiana powinna być wysłana jako osobny commit na repozytorium utworzone w pierwszej fazie. Czas na wykonanie zadania to cztery tygodnie.
Zadanie 2.
Dany jest kod źródłowy strony:
<!DOCTYPE html>
<html>
<head>
<title>Praca domowa nr 6</title>
<meta charset="utf-8">
</head>
<body>
<div class="wrapper">
<h1 class="example">Praca domowa nr 6</h1>
<ul>
<li id="li-1">Punkt 1.</li>
<li id="li-2">Punkt 2.</li>
<li id="li-3">Punkt 3.</li>
<li id="li-4">Punkt 4.</li>
<li id="li-5">Punkt 5.</li>
<li id="li-6">Punkt 6.</li>
<li id="li-7">Punkt 7.</li>
<li id="li-8">Punkt 8.</li>
</ul>
<p class="example">Tu jest treść akapitu</p>
</div>
</body>
</html>
Napisz skrypt języka JavaScript, który:
- usunie klasę elementu <h1>;
- doda identyfikator do elementu <h1> o wartości równej odwróconemu ciągowi znaków rotakifytnedi-ywon;
- doda link w elemencie o klasie wrapper, który będzie miał klasę new-class i który będzie przenosił do strony sealcode.org; link ten powinien mieć atrybut target=”blank”;
- usunie całą zawartość listy a w jej miejsce stworzy nową zawartość, na którą będzie się składać 30 elementów <li> o identyfikatorach o nazwach odpowiednio new1 do new30, z treścią odpowiednio Nowa treść 1 do Nowa treść 30;
- w akapicie pod listą zmieni treść na Zmieniona treść akapitu.
Źródła
- Duckett Jon, JavaScript and JQuery: Interactive Front-End Web Development, przeł. Robert Górczyński, Helion, 2015, ISBN 978-83-283-0126-9.
- kursjs.pl